

What’s kamu? #︎
The goal of kamu is to connect organizations worldwide via decentralized data pipeline and allow efficient and safe exchange of structured data:
- It lets publishers share data easily, having minimal infrastructure, and without giving up ownership of their data
- People can then collaborate on building decentralized data supply chains to clean and enrich raw data
- These pipelines are real-time, autonomous, and require nearly no maintenance
- Consumers of data can easily verify that data comes from trustworthy sources and was not maliciously altered
For a proper introduction please read this blog post or our whitepaper.
What’s new? #︎
Here are some exciting things we’ve been working on in the past 4 months:
Web UI & GraphQL API #︎
So far you’ve seen kamu-cli tool in its “Git for Data” state, where collaboration functions in a pure peer-to-peer way, similarly to how you can use git without GitHub.
Collaborating in this way is possible, but of course has limits. Efficient collaboration requires many more features like discoverability, auditability, permission control, governance.
To move in this direction we are creating a following “vertical slice”:
- People create datasets and pipelines locally with
kamu-cli - Datasets can be shared via registry
- Others can discover datasets through some “single-but-decentralized” place
- They can download the data from its source or even query it remotely and contribute more pipelines steps
This is why we started focusing more on the “back-end” parts of the system.
First, we added GraphQL API. By running kamu system api-server you can start kamu as a server that provides access to data inside your local workspace. It comes with integrated GraphQL Playground, allowing you to easily explore the API and try out queries.
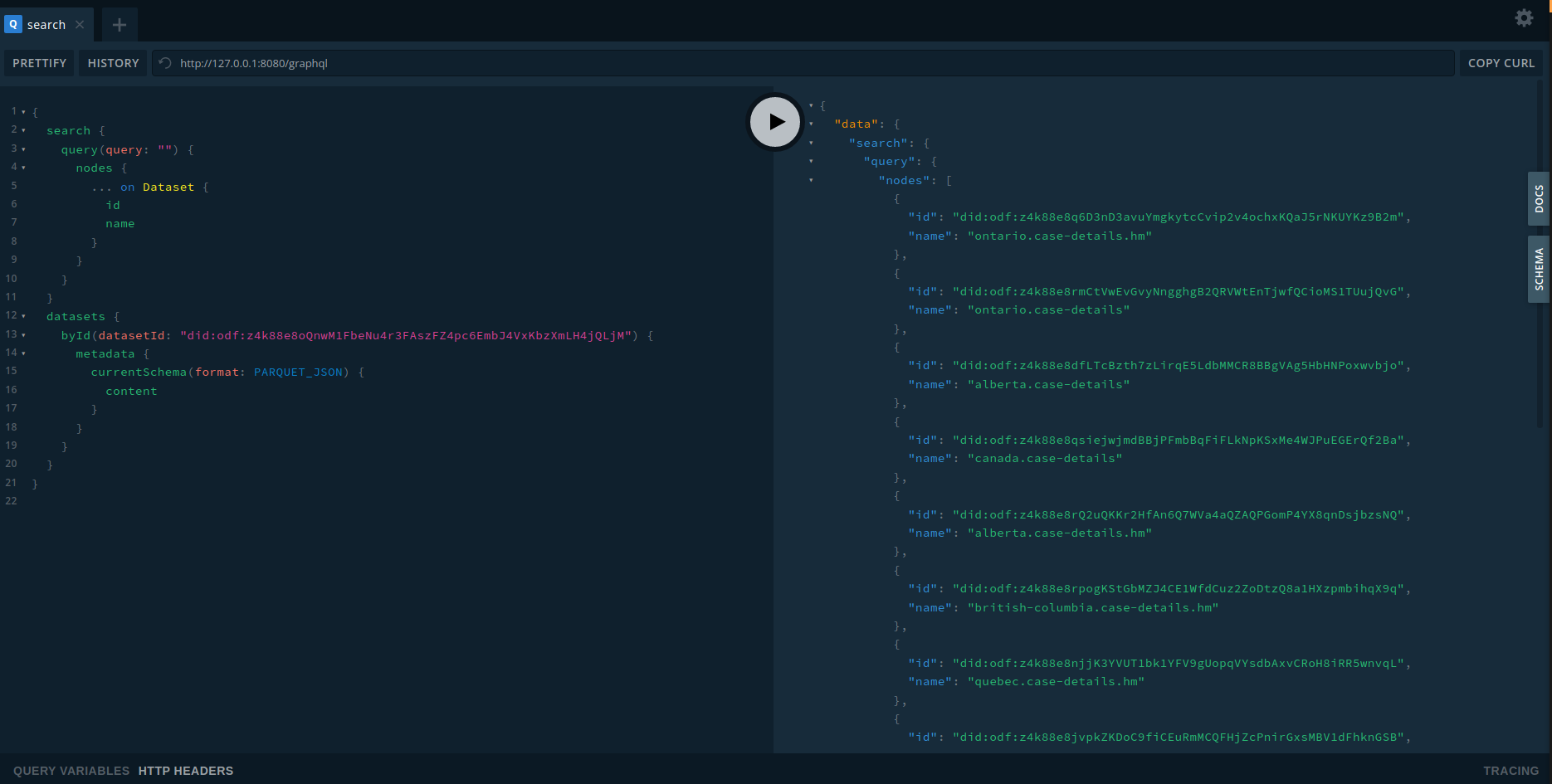
Exploring datasets with GraphQl Playground
We also created a Web UI prototype that connects to the GQL server and lets you discover the data. It is developed in a separate repo but comes embedded into the executable in our release builds, so all you need is to run kamu ui in your workspace.
It currently provides read-only access letting you search and explore datasets:
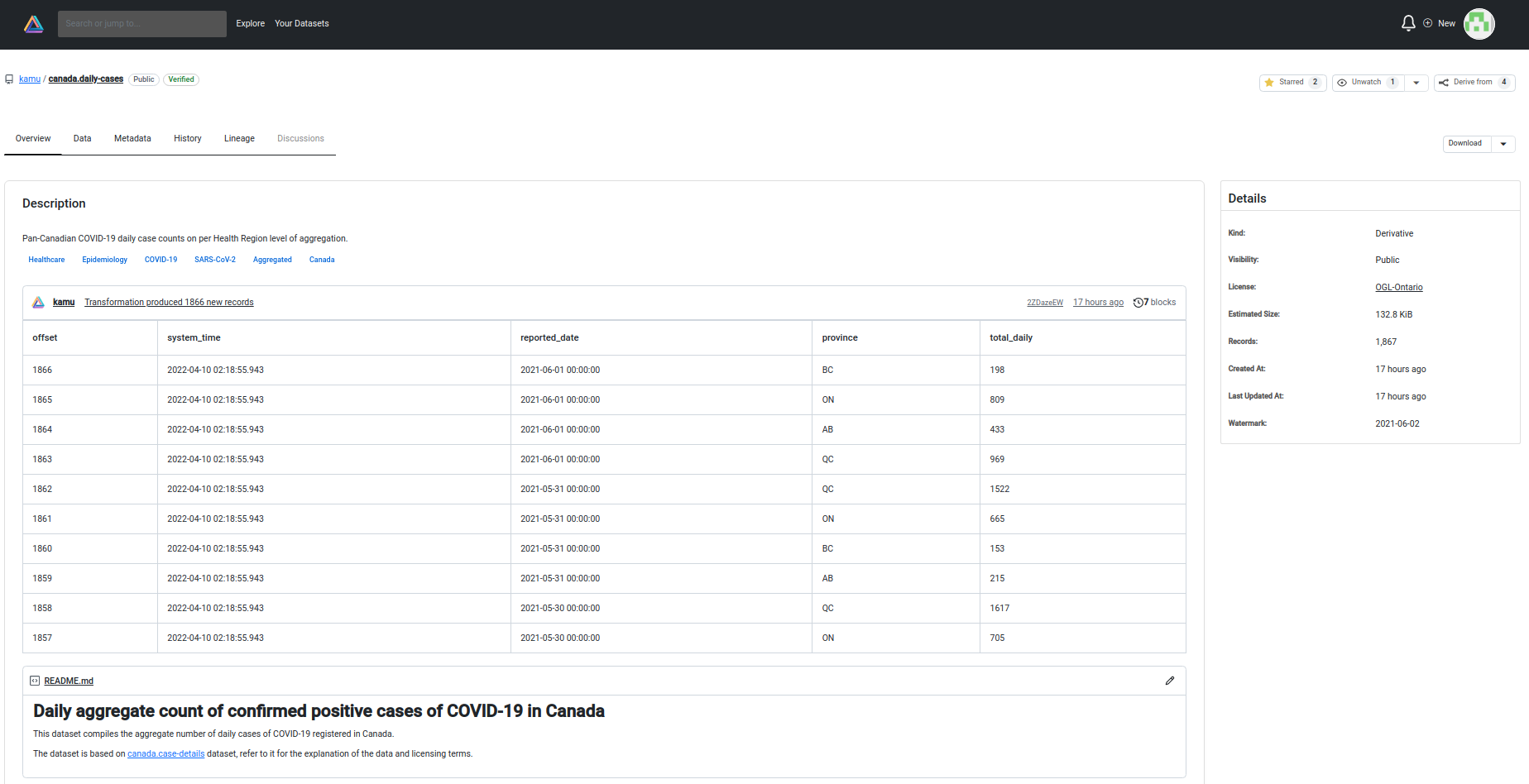
Dataset Overview
You can run ad-hoc SQL queries to explore data (SQL is executed by the integrated DataFusion engine which is super fast):
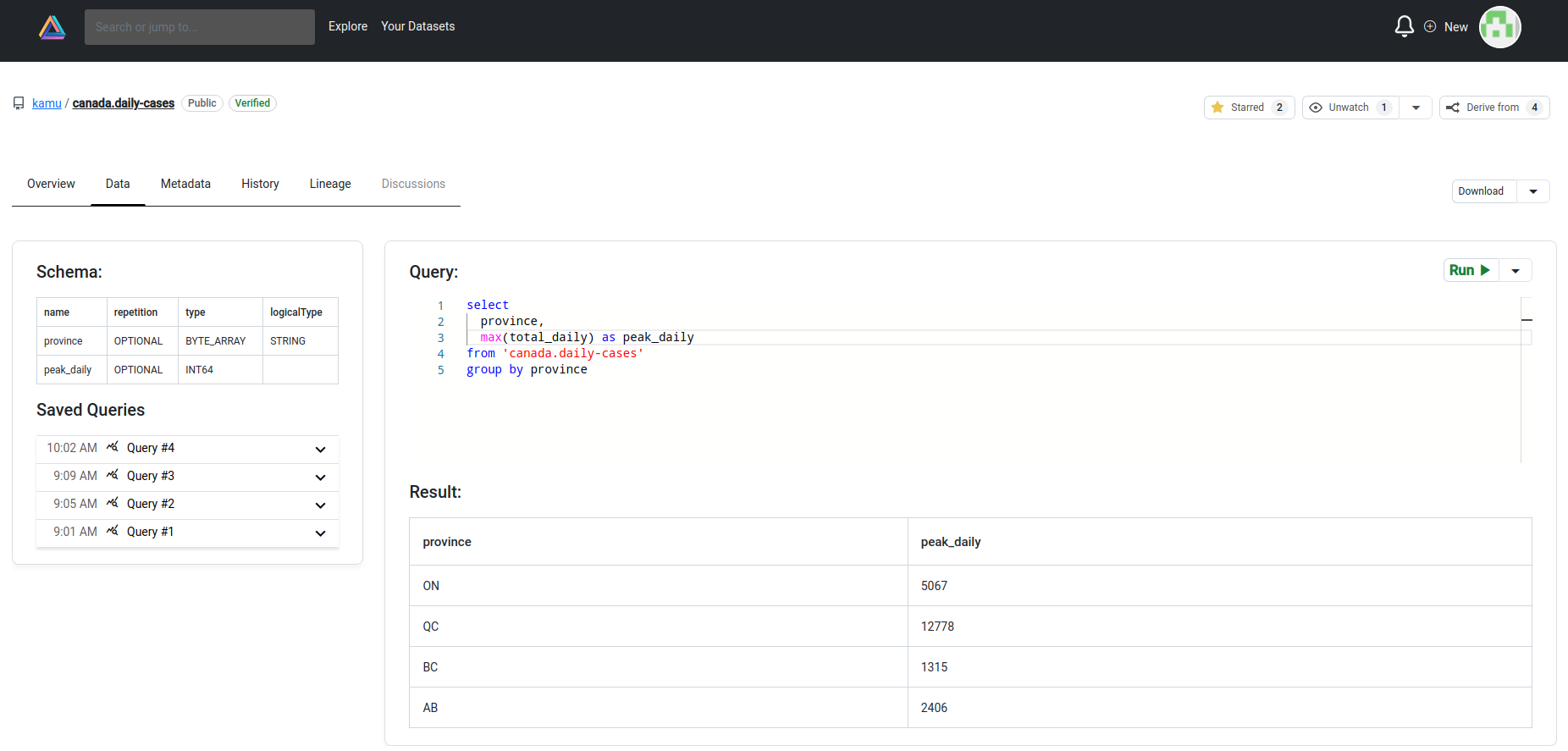
Data Querying
Access metadata chain to see how dataset evolved over time:
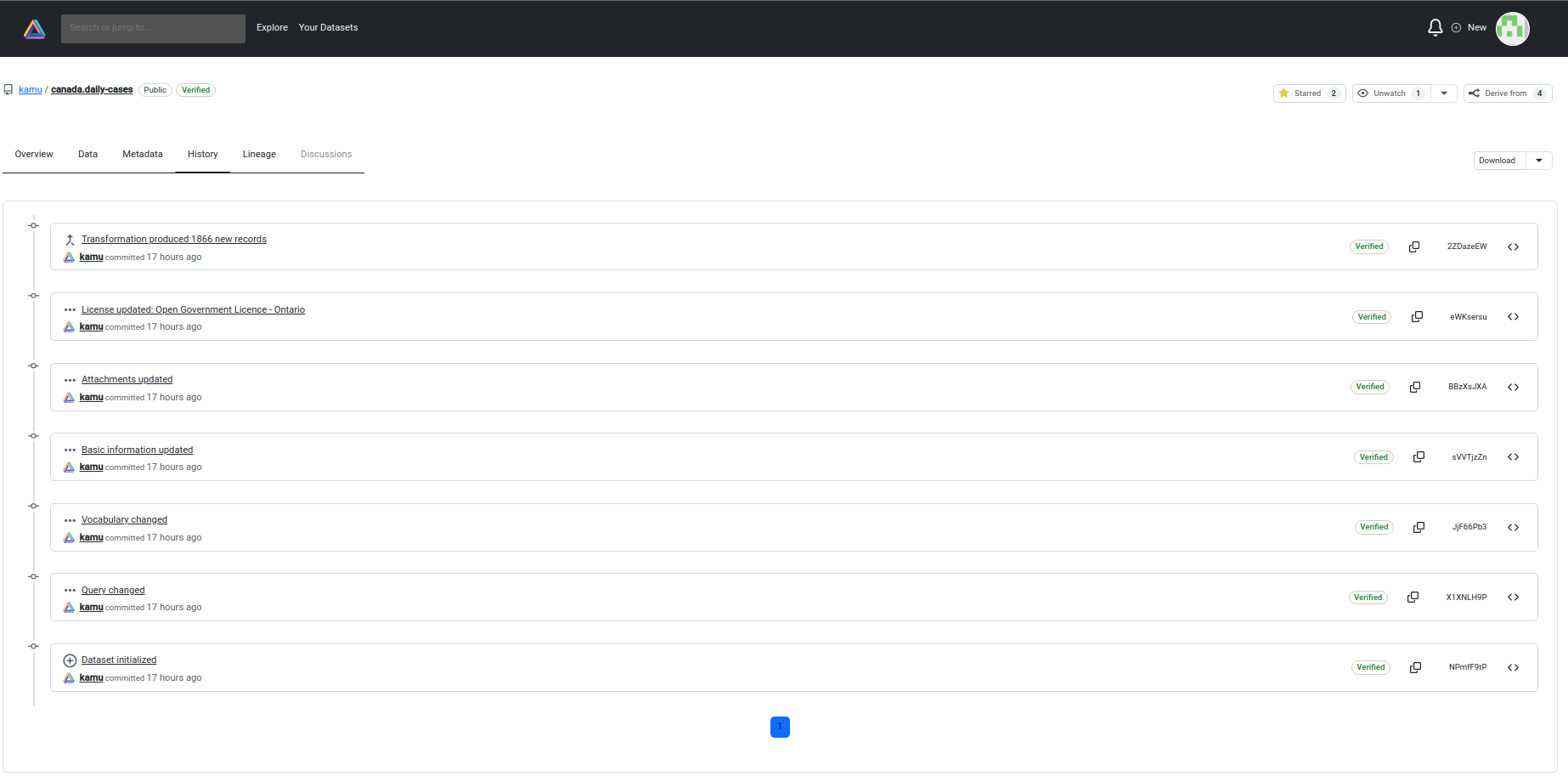
History Tab
And view lineage graph of your pipelines:
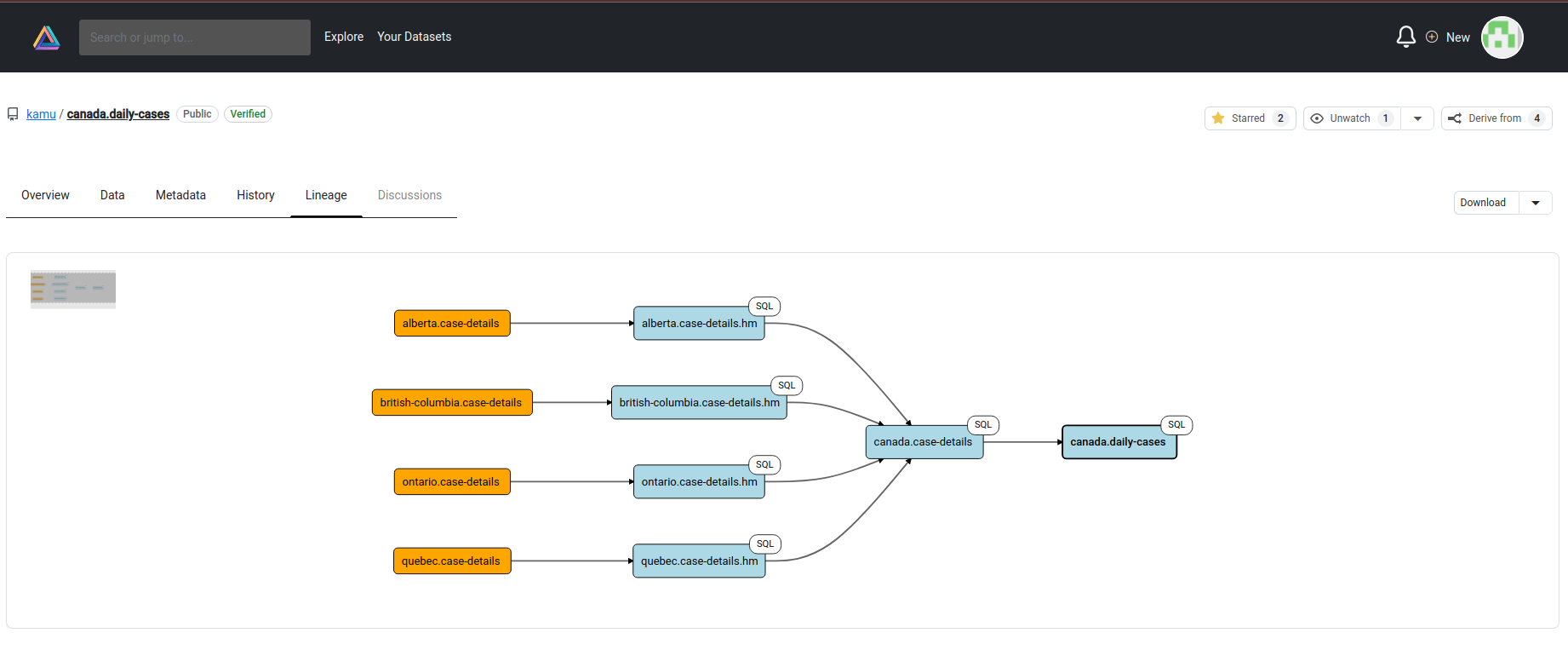
Lineage Tab
To try out Web UI with some sample data without installing anything run:
|
|
Open Data Fabric RFC process and Web3 Direction #︎
We have introduced a light-weight RFC process in the protocol repo to maintain record of all design decisions - see repo for details.
Most notable RFC so far is RFC-003: Content Addressability that bridges ODF with the Web3 world.
It outlines basic principles of content-addressable systems (like IPFS and Blockchain) and how ODF datasets can be stored and named in such systems. Every object in ODF (like metadata block, checkpoint, or data part file) can now be addressed using its hash, meaning that if you have a reference to the latest metadata block of the chain - you can discover the rest of the dataset without any extra information. This lets us store entire datasets in IPFS.
It also proposes an identity scheme where unique dataset ID is derived from a public key - a fully decentralized and practically collision-free way to assign identity that we will further extend into proving control/ownership of a dataset on the network using the private key. Datasets can be distributed / copied / mirrored / stored under different names in a variety of repositories, but still preserve their original identity. The long-term goal is to implement W3C DID specification.
One way to think of this is as turning ODF datasets into NFTs, where, instead of an image, the on-chain part establishes an ownership of a real-time stream of data that is stored off-chain.
This scheme can expand into lots of very cool features like:
- Shared ownership and control, where consent of multiple parties is needed to make certain changes to a dataset
- Mirroring/replication that allows owner to revoke dataset if needed by revoking the associated key
A more detailed post on the future of data in Web3 / Blockchain world is already in the works!
Join Us #︎
If you like what we’re doing - please star our repo and spread the word - this helps a lot!
Kamu and ODF are unique and beautifully complex projects building on the latest ideas in software and data engineering. If you want to take part in revolutionizing the data exchange worldwide - let’s collaborate - we can only achieve this goal together!
We have recently set up a Discord server where you can chat with us and other like-minded people about anything data-related.
See you in the next update!


