
- Overview
- 1. Decentralized source data
- 2. Verifiable derivative data
- 3. Global data sharing
- 4. Using data on blockchains
- 5. Analyzing blockchain data
- Summary
- Bonus: DePIN networks
Overview #︎
As someone who spent 14 years in enterprise data and software and then became a data startup founder, I created this quick course to offer fellow data engineers and data scientists a high-level introduction to the exciting world of “Web3 Data”.
This will NOT be about counting some nonsensical NFTs, or quantitative analysis of a made-up cryptocurrency - this is about data architecture and technical innovations in Web3 that are already shaking up both enterprise and scientific data.
You will learn about:
- Web3 design principles - personal data ownership, decentralized identity, verifiability
- Using data on blockchains - smart contracts and the oracle problem
- Analytics on blockchain data - Ethereum logs and indexers
- Decentralized storage and physical infrastructure networks
To keep things grounded in examples we will implement a data-intensive decentralized weather insurance application along the way.
Web3 technologies are complex, but I assure you that grasping the key concepts is easy. I will navigate you through the buzzword soup and distill the fundamentals.
Throughout this article, I will use a tool called kamu that I’ve worked on for ~5 years to bring Web3 properties like verifiable provenance into mainstream data. The tool packs a lot of cool features behind a simple SQL interface and should be great for someone just dipping their toes into Web3 data. It will let me show you how Web3 concepts can be applied in practice to data lakehouse architecture.
⏩ Short on time? Watch the video of me building the application first, and come back here for the data engineering theory:
Why you should care #︎
I believe that in the next decade, the most significant transformation in the data market will be the shift of focus from internal company data to cross-organizational data exchange.
The real reason why “Big Data is Dead” is that we approached an asymptotic limit of its usefulness. Internal data can help you optimize efficiencies, but it cannot help you (until it’s too late) to see that the market already moved on and you’re optimizing for the product that is no longer needed. Strategic decisions require insights from the outside - government, science, and other companies around you.
Moving data efficiently across org boundaries brings a lot of new challenges:
- How to tell where the data originated from?
- How to tell if it can be trusted?
- How to hold other parties accountable for the data they provide?
- How to not drown in thousands of data sources you rely on?
- How to ensure privacy and fair compensation for data owners?
None of these problems are being solved by existing enterprise data solutions. I often feel like the data exchange today works more despite the state of technology rather than being facilitated by it. To create a global data economy we need better technologies, and this is where Web3 has the most to offer.
When people hear “Web3”, most think about blockchains and their negative baggage, like meme coins, scams, and the NFT craze. The reputation of a “big casino” is unfortunately well-deserved, but this does not negate the fact that a lot of really amazing fundamental technologies are also emerging from the Web3 space.
I see Web3 as the first major experiment in trustless global cooperation and incentives design where some things went right, and some went wrong. So let’s focus today on the successes of this experiment, and their potential to reshape how we work with data.
What we will build #︎
One of the most frequent examples of the utility of blockchain is a decentralized insurance smart contract:
- Alice owns a crop field and wants to purchase drought insurance
- Alice uses a smart contract to apply for coverage
- Bob bids to provide the insurance
- An automated policy is created
- Data from nearby weather stations is used to calculate total rainfall
- if it is above the threshold - Bob is paid the insurance premium
- if below - Alice automatically claims the insurance.
This is a tough data science problem on its own, not even considering the limitations blockchains impose on us, but let’s have a crack at it anyway!
Following along #︎
If you’d like to follow along, use these simple steps:
|
|
See install instructions for details.
1. Decentralized source data #︎
Our system will need to be able to answer one key question:
How much rainfall there was in the area X in the period of time [t1, t2]
But where do we get this data?
The weather data market is an oligopoly with just a handful of players like AccuWeather. If we call their APIs - these companies will have the power to influence any policy outcome, and it will be almost impossible for us to hold them accountable for malicious data.
Web3 follows the decentralization principle where no party can have an outsized influence over the whole network and any malicious activity can be identified and penalized.
I will show you a solution using real data at the end, but let’s start small and just assume that we have access to a bunch of devices across the globe whose data we can use.
We will store device data in kamu which just happens to be the world’s first decentralized data lakehouse - a mix of Snowflake, Databricks, and dbt, that you can easily run on your laptop without sign-ups or accounts.
First, we create a dataset that will store device data:
|
|
Datasets in kamu are often created from YAML files that contain metadata about where the data is coming from, how it’s processed, its license, description, etc.
Here’s how the file looks like:
|
|
We can add new data points directly as:
|
|
But we’ll need a lot more data, so let’s add some pre-generated from a file:
|
|
If you run kamu list you will see that we now have a dataset with a few thousand records in it:
$ kamu list
┌─────────────────────┬──────┬────────┬─────────┬────────────┐
│ Name │ Kind │ Pulled │ Records │ Size │
├─────────────────────┼──────┼────────┼─────────┼────────────┤
│ weather-station-001 │ Root │ now │ 44,641 │ 637.92 KiB │
└─────────────────────┴──────┴────────┴─────────┴────────────┘
YAML files are just templates for how datasets are created, so we can reuse them to create another dataset for a similar device:
|
|
You can get a sample of data using tail command:
$ kamu tail weather-station-001 -n 3
┌────────┬────┬──────────────────────────┬──────────────────────┬──────┬──────┬───────────────────────────┐
│ offset │ op │ system_time │ event_time │ lat │ lon │ precipitation_accumulated │
├────────┼────┼──────────────────────────┼──────────────────────┼──────┼──────┼───────────────────────────┤
│ 44638 │ +A │ 2024-08-04T22:13:51.506Z │ 2024-01-31T23:57:00Z │ 30.3 │ 30.3 │ 40.0 │
│ 44639 │ +A │ 2024-08-04T22:13:51.506Z │ 2024-01-31T23:58:00Z │ 30.3 │ 30.3 │ 40.0 │
│ 44640 │ +A │ 2024-08-04T22:13:51.506Z │ 2024-01-31T23:59:00Z │ 30.3 │ 30.3 │ 40.0 │
└────────┴────┴──────────────────────────┴──────────────────────┴──────┴──────┴───────────────────────────┘
Or drop into SQL shell for exploratory data analysis:
$ kamu sql
> show tables;
+---------------+--------------------+---------------------+------------+
| table_catalog | table_schema | table_name | table_type |
+---------------+--------------------+---------------------+------------+
| kamu | kamu | weather-station-001 | BASE TABLE |
| kamu | kamu | weather-station-002 | BASE TABLE |
+---------------+--------------------+---------------------+------------+
> select max(precipitation_accumulated) from 'weather-station-001';
+----------------------------------------------------+
| MAX(weather-station-001.precipitation_accumulated) |
+----------------------------------------------------+
| 39.99999999999861 |
+----------------------------------------------------+
Or even run integrated Jupyter notebook to visualize it:
|
|
⚠️ It may take a few minutes to download necessary container images
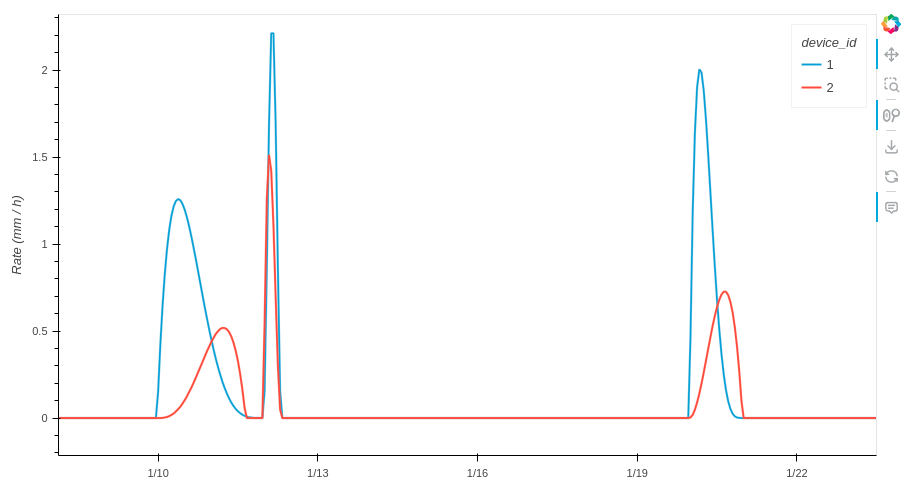
Visualizing generated data in Jupyter
Let’s take a close look at how data in kamu is stored under the hood and compare it to traditional systems.
1.1. Content Addressability #︎
Apache Parquet format has become a de facto standard of the enterprise data. The data we just ingested was written as Parquet files too, but with a slight twist: every file was named after the SHA3 hash of its content, thus making .kamu workspace directory a content-addressable file system.
You already work with content-addressable systems daily - peek inside any .git/objects directory and you’ll see just a bunch of hashes.
The idea of content-addressability is fundamental to Web3 as a whole and to decentralized file systems like IPFS.
In cloud storages like S3, the URL serves as both file’s identity and its location (region, bucket), e.g.:
https://s3.us-west-2.amazonaws.com/datasets.kamu.dev/covid19-cases.yaml
If we move the file from S3 to GCS - our users will not be able to find it by the same URL any more as the location has changed. Files in IPFS can migrate from one computer to another, and be replicated across thousands of hosts worldwide, so their location changes very frequently. By using content hashes we simultaneously:
- Avoid the problem of giving files globally-unique names (which would necessitate some central registry like DNS)
- Have users refer to data using its identity, and let the storage system figure out where to find it.
Using content-addressability allows kamu to both work with conventional cloud storages and natively support decentralized file systems where:
- A single dataset can be split across multiple independent hosts
- Stakeholders can replicate data from one another and act as “mirrors” to make sure data doesn’t disappear and is highly available
- Data owners can easily change infrastructure providers without affecting data consumers
- Data within one datasets can do hot/cold storage tiering transparently to end users.
1.2. Cryptographic ledgers and Merkle DAGs #︎
Parquet files are a fairly low-level primitive for storing raw data. Modern data lakehouses additionally use formats like Apache Iceberg and Delta to provide a high-level “table” abstraction on top of a bunch of Parquet files.
Kamu uses Open Data Fabric (ODF) format which is a Web3 counterpart of Iceberg and Delta.
ODF dataset consists of a chain of “metadata blocks”. Similarly to git log, if you run:
|
|
You should see five blocks that show our dataset being created (Seed), source and schema defined, and then several slices of data added.
ODF metadata is a cryptographic ledger:
- Ledger - because it describes a complete history of events
- Cryptographic - because blocks reference data in Parquet and one another by their hashes.

Cryptographic ledger
When one file identified by its hash references another file by its hash - you get a data structure called Merkle DAG.
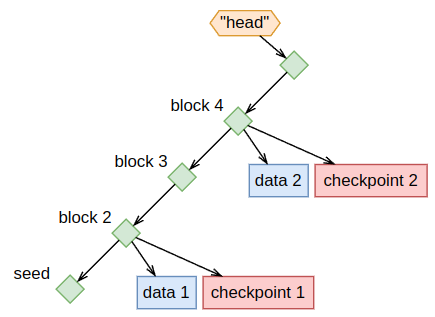
Dataset as a hash graph of metadata and data
If I give you a top-level hash of some ODF dataset you’ll be able to traverse the entire history of the dataset (from most recent events to oldest) by using hashes as pointers to the next file. This is very similar to navigating the Git commit history and exploring blockchain transactions on Etherscan.
Using hashes you can refer to the exact point in history of any dataset and ensure that data you see is bit-for-bit identical to the original and was not maliciously changed in transit (tampered).
1.3. Immutability #︎
An interesting consequence of hash graphs is that all data is immutable. In ODF, a dataset can only change by adding new blocks to the end.
We found this to have an extremely positive effect that gives consumers of your data full visibility of how it has evolved over time - not a single record can appear or disappear without a trace.
This structure encourages working with data in event form instead of Change-Data-Capture, and dealing with data inaccuracies through explicit retractions and corrections.
Note that features like compactions, repartitioning, and GDPR compliance can still be implemented in this model, as parties that replicate the data can agree to “collectively forget” about some Parquet files after certain conditions are met (e.g. a compacted file correctly merges all records). Metadata chain will remain as a permanent record of what took place, while the data is replaced.
1.4. Identity and ownership #︎
Notice that instead of one big weather-stations dataset, we created two separate datasets per device - this is to facilitate personal data ownership.
Putting individuals in control and avoiding centralized authority is at the core of Web3, so when it comes to data - we want every device to be potentially owned and maintained by a different person.
They would:
- Own the data they collect
- Control where data is stored and who has access
- Decide where to contribute this data and for what fee
- Be responsible and held accountable for the validity of the data.
Expressing that “Alice owns device-001” is, however, quite difficult to achieve in a decentralized way. We already mentioned that even giving something a unique identifier seems impossible without a central service.
Web3 solves decentralized identity using cryptography. In almost every corner of it you will encounter W3C DID decentralized identifiers that look like this:
did:key:z6MkhaXgBZDvotDkL5257faiztiGiC2QtKLGpbnnEGta2doK
DID above is a seemingly random piece of data, and randomness is another way how we can uniquely name an entity without a central service - by relying on near-zero probability that someone else picks the same name.
It is different from UUID because this random string is actually a Public Key that has an associated Private Key. Keys are created at random but are linked together. The creator of DID can thus prove to anyone that they are in fact the owner of this name using asymmetric encryption. They can also sign various data to put their “seal of authenticity” on it.
Our “Alice owns device-001” relationship thus can be expressed by signing Alice’s DID with the device’s private key, as no one else but the owner of the device would be able to do so.
In ODF data format every dataset has an embedded DID. You can find them in your datasets using kamu log command:
|
|
|
|
Or via:
|
|
Because metadata is a cryptographic ledger - no one can change the DID after the dataset is created, so everyone in the world will know who the data belongs to. Every ODF dataset therefore is a unit of ownership.
1.5. Meanwhile in Web2 #︎
Enterprise data solutions are designed to work within company boundaries, where everyone’s incentives are roughly aligned. They are not made to withstand continuous adversarial actions that are a regular occurrence in the multi-party world.
Formats like Iceberg and Delta are not tamper-proof, but more importantly, encourage routine loss of history. Due to over-reliance on CDC and compactions that leave no trace, data can change dramatically from one version to another without any explanation. On a global scale, this makes it very hard to establish trust relationships between data producers and consumers, and especially hard to automate things downstream. Every day a consumer has to expect that ALL data may change - this complexity poisons all downstream pipelines.
Because identity and signing are not part of these formats - authenticity of data cannot be confirmed, accountability cannot be established, and data is left susceptible to the copy problem.
Web3 has all the answers to create lightweight “passports for data”, so that all data that travels on the web is verifiable, and can be traced back to its origin.
2. Verifiable derivative data #︎
Ownership is important, but working with potentially thousands of different datasets will get messy fast.
We prefer the convenience of having all device data in one big global dataset … but if we simply copy the data - we will throw away the personal ownership and control that we worked so hard to achieve. 😰
This is where kamu’s derivative datasets come to help:
|
|
┌─────────────────────────┬────────────┬─────────────┬─────────┬────────────┐
│ Name │ Kind │ Pulled │ Records │ Size │
├─────────────────────────┼────────────┼─────────────┼─────────┼────────────┤
│ weather-station-001 │ Root │ 2 hours ago │ 44,641 │ 637.92 KiB │
│ weather-station-002 │ Root │ 2 hours ago │ 44,640 │ 636.71 KiB │
│ weather-stations-global │ Derivative │ an hour ago │ 89,281 │ 1.01 MiB │
└─────────────────────────┴────────────┴─────────────┴─────────┴────────────┘
Derivative datasets are not allowed to access any external data - they can only apply purely deterministic transformations to data already in the system.
Here’s how weather-stations-global.yaml looks like:
|
|
Here we do a very simple UNION ALL to merge data from all datasets into one.
🚩 kamu does not implement SQL engine itself, instead it integrates multiple open-source engines through small adapters. The above query uses Apache DataFusion engine, but could also use Apache Spark, Flink, RisingWave, and more. Engines run in container sandboxes ensuring that the computations are deterministic.
2.1. Verifiable computing #︎
Derivative datasets are an example of verifiable computing - the ability of one party to validate the computations performed by another party.
If you launch kamu’s embedded web interface:
|
|
and go to the “History” tab of the weather-stations-global dataset, you’ll see that it recorded every processing step that was performed. The ExecuteTransform block contains DIDs and block hashes of each input, hashes of data produced as the result, and more.

If we send this dataset to someone else, they can run:
|
|
And verify that this dataset fully corresponds to its inputs and declared SQL transformations.
The idea of verifying computations by reproducing them is at the core of Ethereum and many other blockchains.
Another cool way to look at this is we could send someone only the metadata chain, and have them reconstruct the identical dataset by re-running all computations. Or we can drop data of datasets that are not frequently used, and reconstruct them on demand!
🚩 If we used regular batch SQL - verifying every transformation would get progressively more expensive over time, so derivative transformations in kamu use stream processing. Try adding another data point to one of the inputs and pull the derivative dataset again - in the metadata, you will see just one extra record added. All processing is incremental, and using streaming-native engines like Flink and RisingWave you can express powerful operations like stream-to-stream JOINs.
See our whitepaper for details.
2.2. Lineage & provenance #︎
A neat “side-effect” of verifiable and reproducible computing is that we also get verifiable provenance. Metadata can tell us exactly where every single bit of derivative data came from, and what inputs and operations were used to produce it.
The “Lineage” tab shows the pipeline we just created:
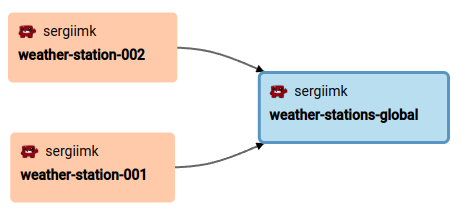
While tools like dbt and Manta also provide similar lineage graphs for SQL, there is a huge difference: the provenance you get from kamu is cryptographically secured and verifiable - it’s impossible to fake.
In enterprise systems, lineage is something you “bolt onto” an ETL pipeline as a best-effort hint, but in kamu it’s impossible to transform data without creating provenance. When we share derivative datasets online - everyone will be able to tell which data sources were used, audit our SQL, and decide whether to trust our data.
This is why when we combine individual device datasets into a global dataset, we don’t jeopardize data ownership - original owners can be easily inferred from derivative data, no matter how many processing steps it went through.
2.3. Meanwhile in Web2 #︎
If you internalize the above, you will never look at the datasets that someone “cleaned up” and shared on GitHub, Hugging Face, and Kaggle the same. In the world of AI, where entire companies exist to generate realistic-looking data, a dataset whose authenticity cannot be established will soon have no value.
Malicious intent aside - people make mistakes. When some data point in a report “looks off” - it can take weeks or months in a large organization to trace where it came from and see whether it’s correct. Fine-grain provenance provides a way to quickly settle such doubts, and avoid decision-makers defaulting to their gut feeling.
Verifiable computing is the only way to transform authentic data and not end up with results no one can trust. It’s a prerequisite of global collaboration on data. In combination with streaming SQL it allows to build autonomous cross-organizational ETL pipelines that reward data providers and pipeline maintainers for their contributions!
3. Global data sharing #︎
Notice that so far we used kamu purely on our laptop, so why do I call it a “decentralized lakehouse”?
Kamu follows an important local-first principle, where all software is designed to run in isolation, without any accounts, or even Internet connection. Imagine if you could run parts of AWS or Google infrastructure on your laptop for small projects and testing - this is the direction many Web3 software products are taking - we make software openly available, and participation in networks voluntary.
But as we come closer to deploying our application, let’s see how to make our data available online.
There are multiple ways to share data in kamu. You can push your datasets to cloud storage like S3, or decentralized file systems like IPFS to share it with others in a peer-to-peer way. But because our contract will need to query data with SQL - we need both storage and API.
Kamu Node is a decentralized compute layer for ODF datasets. Node shares 95% of functionality with our CLI tool but is made to run as a server.
You can deploy and use it for free. But just like most of us don’t run our own Git servers and prefer the convenience of GitHub - you’ll usually delegate running a node to someone else. Remember, even a malicious node can’t possibly mess up your data without being exposed!
We will use Kamu’s demo environment - just one node out of many operated by the ODF community.
To upload datasets run:
|
|
You should now be able to find your datasets in the node’s web interface, which is the same UI you saw in the tool.
You can also access data through a bunch of APIs, including REST:
|
|
By using open-source data engines, open formats, and protocols - Kamu creates a non-custodial global data sharing network. A network where data remains on the infrastructure of individual publishers, but can be queried as a single database through federation, and collaboratively processed by a web of derivative data pipelines.
3.1. Meanwhile in Web2 #︎
Enterprise lakehouses are converging on similar technologies (Iceberg, Arrow, SQL), to the point where it’s hard to tell the difference between them (except for incompatible SQL dialects), yet migrating between them remains extremely hard. Many leading cloud solutions don’t even provide on-premise deployment options, which is often a deal breaker for government, healthcare, and science. For global data exchange to work - their entire business structures will need to be revisited first, to create the correct incentives.
Building data solutions with tamper-proof formats and verifiable computing allows for a clean separation of data ownership, storage, and compute infrastructure. Infrastructure can be outsourced without ever feeling that your data is being held hostage, as changing infrastructure providers can become a matter of days, not years.
4. Using data on blockchains #︎
Now that we have a solid foundation for device data, it’s time to figure out how to implement the insurance broker.
Once again, we cannot develop the broker as a regular app, as our goal is not to have any central points of control, including ourselves! So instead we will develop it using Ethereum smart contracts as a so-called decentralized application (DApp).
A quick primer on smart contracts:
- Smart contracts are pieces of compiled code that, just like Java, are executed by a virtual machine
- The code is uploaded to a blockchain in a transaction and forever becomes part of its cryptographic ledger
- Every person who runs a node will have a copy of your code and a state associated with the contract execution
- Functions on smart contracts are called within transactions
- Functions can modify contract state
- The caller of a function pays for the state storage and every compute operation executed by the virtual machine
- For a transaction to be valid, every blockchain node executing a function has to end up with the same state.
Once again we see verifiable computations via determinism and reproducibility
4.1. Smart contract #︎
If you want to follow along this more complex part - see the readme file in the repo, but for those interested only in the data story I will provide just the key concepts.
Our InsuranceBroker contract has three key functions:
|
|
Alice calls this function with information about her field location, the minimal rainfall level she expects to see, and other parameters.
|
|
Bob (the insurer) calls this function to propose a policy. In our example contract, we simply accept the first bid.
|
|
Called to initiate the policy settlement. It exists simply because there is no such thing as calling a function on a timer in Solidity.
In this function, we will need to somehow get the data and make a policy decision.
4.2. The Oracle Problem #︎
Because smart contracts must be deterministic - they are not allowed to use any external information. They can’t access APIs, read files, or make system calls, they can only use data already on the chain. This makes accessing external data challenging.
The only way to get data onto a blockchain is to create a transaction and pass it as a parameter to a function call.
Pause and consider, who could send such a transaction.
-
It cannot be Alice or Bob - both obviously have a financial incentive to settle the policy in their favor.
-
It cannot be us, contract owners - that’s too much power to have.
One possible solution is to make device owners write data directly to the blockchain - this seems perfect as they would retain personal ownership of data.
However:
-
Storing data on-chain is crazy expensive, as every node will have to have a copy of your data forever. The cost of storing just one day of data from a global weather network will be in hundreds of thousands of dollars.
-
Raw device data will have to be processed within a smart contract. Even if we could implement an SQL query engine in Solidity, the network would charge a fortune for performing these computations.
The difficulty of accessing off-chain data in a trusted way is widely known in Web3 as The Oracle Problem.
4.3. ODF Oracle #︎
Here Open Data Fabric has another ace up its sleeve - it specifies how data in ODF format can be queried from blockchains.
Here are the relevant parts of the contract:
|
|
How it works:
_oracle.sendRequest()is a call to a very simple contract that stores parametrized SQL requests on the blockchain- Kamu Nodes globally can periodically check blockchains for such requests
- If they see a dataset DID they know about - they will race to provide an answer by calling
OdfOracle.provideResult()contract function OdfOraclecontract then dispatches results to callback functions - in our caseInsuranceBroker.onResult()
You can find example contract transactions on Etherscan blockchain explorer:

Contract transactions on Etherscan
Why does this work while sending results directly doesn’t?
Once again we rely on verifiable computing:
- Along with response data, nodes provide information about which state of data (block hash) the query was executed on
- Together with transaction signature this constitutes a cryptographic commitment of a node to the response
- Anyone can use it to hold the node forever accountable for the given response
- Anyone can try to reproduce the same request and verify it against the commitment.
It’s almost like we have smart contracts on both sides:
- On blockchains, we do OLTP using general programming language (Solidity)
- In
kamu, we do OLAP using verifiable streaming SQL.
Kamu therefore provides a way to store and process massive volumes of data off-chain and get small verifiable results on-chain for high-level logic in smart contracts. This is done as cheaply and effectively as any enterprise data solution while providing a way to financially penalize malicious actors.
4.4. Meanwhile in Web2 #︎
Many data-intensive applications are built on top of APIs of giants like Google, AccuWeather, and Bloomberg. Not only do you have no idea where their data is coming from, but their APIs don’t even sign responses, meaning you can never hold these companies accountable for data they provide.
All they have is a perceived status of “reliable providers”. This status is very hard to achieve for a small data company entering the market, thus the trust problem hurts both consumers and providers and further entrenches the tech giants.
Web3 offers a path out of this flawed state.
5. Analyzing blockchain data #︎
Have you ever deployed an application to production and found yourself wondering: Is anyone using it? Is it running fine? We have the same problem with our smart contract. We can look at individual transactions on Etherscan, but how do we set up proper monitoring, alerts, and dashboards?
Blockchains can be seen as giant open datasets, so let’s see how we can set up the analytical side of our decentralized application.
5.1. Ethereum logs and events #︎
Besides the contract state, where we store active insurance policies, Ethereum provides a separate storage area called “logs”. Unlike state, logs are write-only and much cheaper.
To use it in our contract we define event types:
|
|
And emit events in relevant places:
|
|
The contract state is like our OLTP database, and logs are like Kafka.
Well-written contracts will thoroughly design and document their events, so blockchain analytics is done primarily on them.
5.2. Accessing log data #︎
Log data can be retrieved from any blockchain node using the standard JSON-RPC API eth_getLogs function.
Many public Ethereum nodes accept transactions for free, but since no real money is tied to calling eth_getLogs - most nodes ban this function to prevent abuse.
We are left with options of:
- Running our own Ethereum node, which is not something I would do on a laptop
- Renting a node from a large set of node operator companies which often have very generous free tiers.
Note that eth_getLogs function doesn’t know anything about your contract - it returns log data as a raw binary, so the combined task of getting log data turns into:
- Renting a node
- Writing code to call
eth_getLogswith correct filters - Paginating through ranges of millions of blocks
- Decoding binary data into structured events using data from your contract
- Storing events in a database to query later.
This is a lot of work, and I wouldn’t recommend doing it yourself.
5.3. Blockchain indexers #︎
There is a range of projects called “blockchain indexers” that provide you SQL / GraphQL interfaces for blockchain data. Many of them literally take all the billions of logs and transactions from blockchains and put them in Snowflake or their own Spark clusters.
This creates a major issue: they take decentralized verifiable data from blockchains and store it in enterprise data warehouses - they re-centralize data.
Those in control of the warehouse control what you see in your analytics.
There is some safety net in the fact that raw events are always available on Ethereum for you to cross-validate with the warehouse, but these platforms don’t offer any local option either, so:
- This task becomes comparable in effort to writing your own indexer
- This does not protect you from the indexer flipping the switch on you and leaving all your dashboards non-functional.
Getting the job done for most is more important than “Web3 purity”, yet even so indexers fail. Unless your off-chain data is in Snowflake and you pick an indexer that uses Snowflake - you will end up with two data warehouses with no ability to query across them.
In our case we really care that insurance policy data is queryable alongside device data, as this would let us do all kinds of cool things, like continuously predicting the risks of claims.
5.4. Reading blockchain logs with Kamu #︎
With kamu, you can read data directly from most blockchains and store it alongside your off-chain data.
Here’s how:
|
|
We created three datasets, per each event we want to analyze. The dataset files look like this:
|
|
How this works:
- We declare
EthereumLogsdata source (reference) chainIdandnodeUrlspecify which network and node to usefilterworks just like SQLWHEREclause to pre-filter raw logs by address, block number, and topicssignatureis just a copy of event declaration from our source codepreprocessstep uses more SQL to further transform the event.
kamu will use all the above to create the most optimal RPC request to the node and will stream the data in.
Once you have the data you can try to explore and visualize it in Jupyter, but what I did instead is push data to Kamu Node and connect Apache Superset to build a nice BI dashboard:
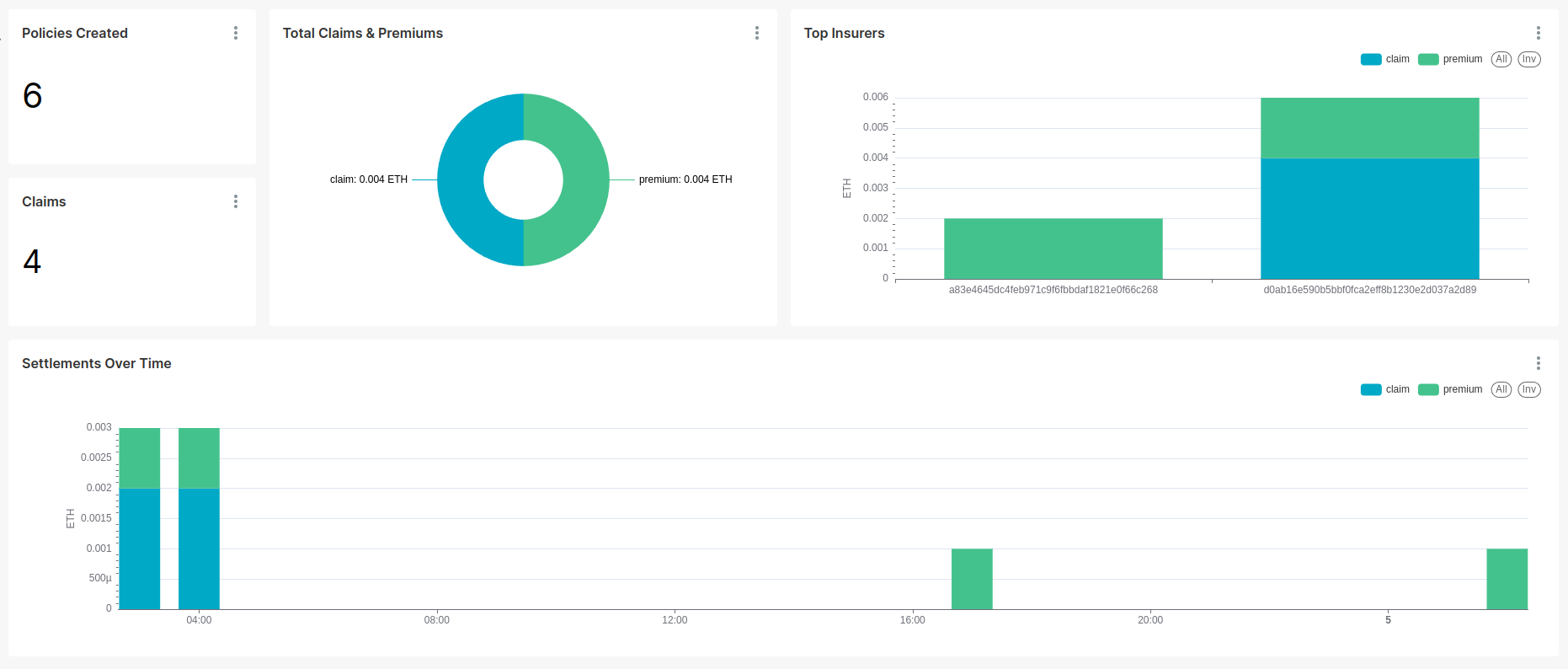
Contract dashboard in Apache Superset
I then configured the node to update my datasets every 10 minutes to have near real-time data.
Summary #︎
What we’ve built today is not a small feat. It’s a realistic vertical slice of:
- Decentralized data publishing and personal data ownership
- Data-intensive application that has no central authority
- Verifiable off-chain processing of large volumes of data
- Analytics on blockchain data without re-centralization.
It’s also important that we managed to:
- Build and test every component on our laptop
- Outsource the infrastructure to a third party without sacrificing the security of data
- Build almost everything with just SQL, a few YAML files, and notebooks.
It’s still a toy app, but it should be easy to see how it can be extended with many cool features, like:
- Automated auction for insurance coverage
- Detecting outliers in device data
- Rewarding device operators with a percentage of insurance premiums
- Distributing rewards proportionally to the amount and quality of data contributed.
Bonus: DePIN networks #︎
The network of independent weather device operators that we envisioned as the source of our data actually already exists as the WeatherXM project. You can purchase a device from them and earn cryptocurrency for running it in your region.
This concept of community-operated devices that earn for providing data or compute resources is known in Web3 as decentralized physical infrastructure networks (or DePIN).
Every day WeatherXM publishes data collected from all devices to IPFS - a decentralized file system.
Let’s get this data with kamu, and while we’re at it also grab an open dataset of USA Counties from ArchGIS:
|
|
⚠️ Expect a ~600MB download
You should see a few million records ingested:
|
|
And a quick query shows that it contains data from over 5K devices:
|
|
As the last bit of data science fun, start the Jupyter notebook and execute the real-depin-data.ipynb:
|
|
You will see how easy kamu makes using powerful engines like Spark and Apache Sedona to do geospatial JOINs:
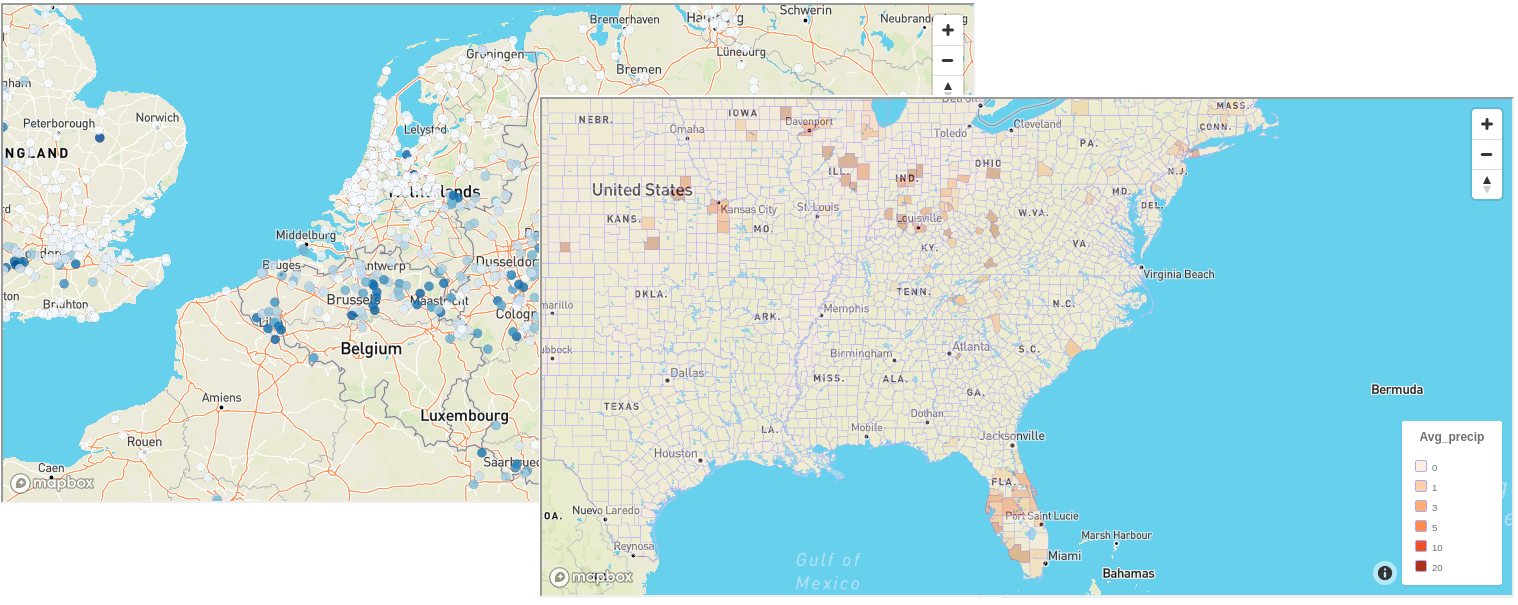
Visualizing WeatherXM data in Jupyter
It should be fairly straightforward to incorporate this data into our project so I will leave it as an exercise.
The point is that:
- This data is real
- This decentralized IoT network is real
- And the incentive mechanism behind it appears to be working!
Web3 is happening, and data science stands to benefit significantly, as projects that may have nothing to do with blockchains adopt the ideas of tamper-proof data and verifiable provenance.
I’m personally most excited about how the ability to verifiably clean, enrich, and transform data will change how we collaborate on data globally.
So I hope you enjoyed this quick tour, and that it will motivate you to pay closer attention to this space, or even dive in head-first like I did. 😅
Every star on GitHub helps the project going.
And if you’d like to learn more - check out other tutorials here and join our open data science community on Discord.


