

- The Challenge of Factual Data in LLMs
- Retrieval-Augmented Generation
- Introducing Oracle-Augmented Generation
- OAG vs. RAG
- OAG and Kamu for Data Supply Chain Verifiability
- Role of OAG in AI and Data Economy
- Future work
In collaboration between Kamu and Brian we are excited to introduce a new technique for connecting LLM-based AI agents to verifiable data we call Oracle-Augmented Generation.
You can find a quick overview of the technique in this video:
In this post we will quickly set the stage and then dive deeper into technical and implementation details.
The Challenge of Factual Data in LLMs #︎
Large language models (LLMs) have become very powerful reasoning and automation tools. Trained on vast quantities of data they rely on generalization to extract concepts, find rules and patterns, and infer relationships between them.
The model training is akin to multi-dimensional approximation or lossy compression. The generalization of knowledge that gives models their power of high-level reasoning is the same thing that takes away their ability to manipulate accurate factual data points. Asking models to recall specific facts often leads to “hallucinations” - models making up plausible-sounding but false information.
Embedding the world’s factual data into LLMs not only would be impractical from the model size perspective, but because such models take months to re-train they would also be always lagging far behind the real-time data the world is increasingly relying on for decision-making.
Retrieval-Augmented Generation #︎
To address this, many AI systems employ Retrieval-Augmented Generation (RAG), pairing LLMs with vector databases to retrieve contextually relevant information at the time of the query.
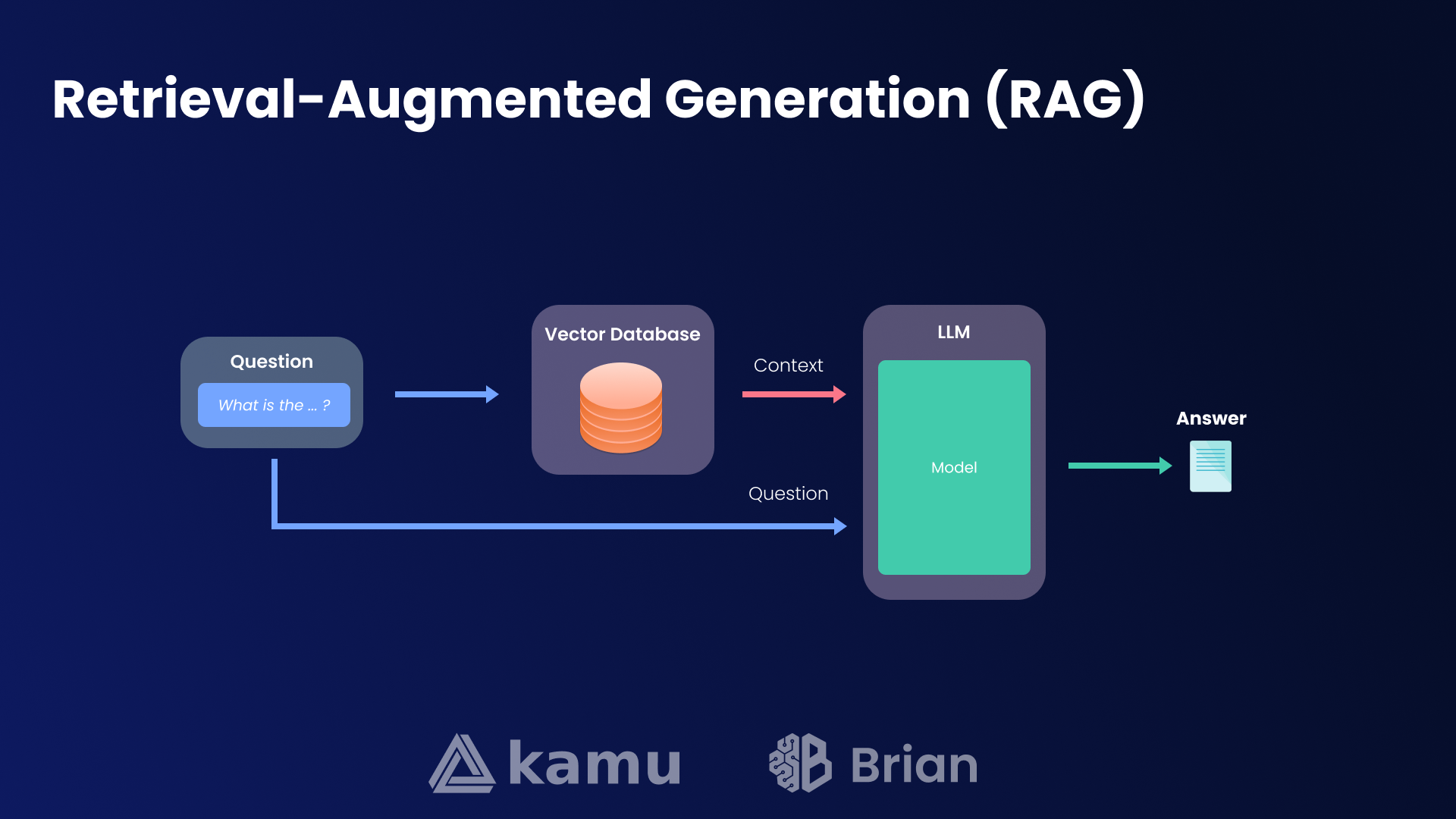
Retrieval-Augmented Generation
While this approach improves the factualness and recency of responses, it has notable drawbacks:
- Source staleness and credibility - major LLM companies employ RAG mostly to search for relevant web pages, lots of which may contain outdated or unreliable information. While different ranking mechanisms are employed to pick the best results, it is difficult to imagine a sustainable approach to assigning and maintaining such ranks on a global scale.
- Complex query conditions - RAG performs best when required information already exists close to its desired form, a form that can be easily processed by an LLM. But the number of questions with non-trivial conditions (e.g. narrowing down geographically, or by time) is so large that we cannot expect a web page to exist for each of them - answering a question correctly may require non-trivial computations over a large amount of data to be performed uniquely for that user.
- Opaque data selection and centralized control - The RAG operator has full control over which sources are included in search results and which aren’t, raising concerns about transparency and potential bias. The proprietary data collection pipelines built by LLM companies to improve model training and RAG also have an adverse effect of concentrating an alarming amount of power in very few hands.
Introducing Oracle-Augmented Generation #︎
We propose a new technique called Oracle-Augmented Generation (OAG) that pairs an AI agent with a verifiable analytical data processing system working with a set of trusted data sources.
The term “oracle” here is borrowed from the domain of Web3 and blockchains where “oracle” is a system that acts as a bridge between blockchains and the external world, enabling smart contracts to access off-chain data while providing some form of guarantees of the validity of data. The term “oracle” also exists in computational theory as a black-box function or device that can answer queries that might otherwise be difficult or impossible to compute, as is the case for recalling facts from a generalized language model.
On the high level OAG proceeds in 4 stages:
- Context gathering - where in its simplest form the Oracle system is asked to provide top N most relevant datasets to user’s question
- Query generation - where the LLM is asked to use dataset metadata to generate a query (e.g. SQL) that computes data that may answer the question
- Query execution - where Oracle performs the query and returns a verifiable result
- Answer generation - where LLM is asked to interpret the data from the query result to the user
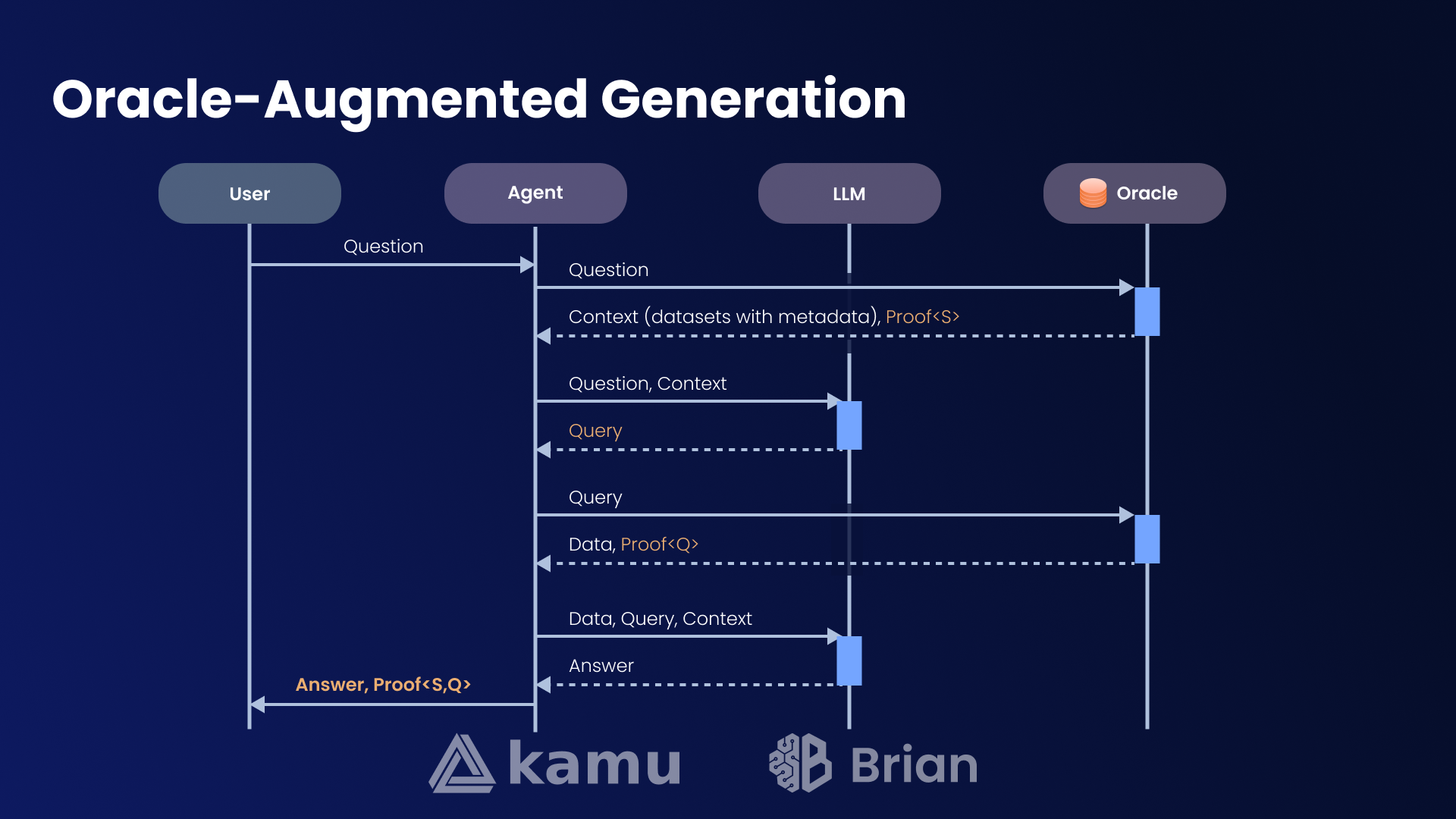
OAG Sequence Diagram
A key distinction from typical “Text-to-SQL” approaches here is the requirement for oracle to provide cryptographic proofs for context gathering and query execution stages.
Example Interaction #︎
Using Brian LLM agent and Kamu Node playing the role of an oracle, let’s see how one OAG user interaction may look like.
User Prompt: What was the total trading volume of USDC between Oct 10th and Oct 20th 2024?
Context gathering: Brian agent passes the prompt to Kamu Node’s search API verbatim, and Kamu will perform a semantic search to find datasets that are most relevant to this question, returning datasets like:
kamu/io.codex.tokens.olhcv- DeFi trading data, most relevant to uskamu/com.cryptocompare.ohlcv.eth-usd- a crypto exchange dataset that has mentions of trading volumeskamu/com.defillama.tokens.prices- crypto token prices dataset that has mentions ofUSDC
Brian agent fetches lots of metadata about these datasets from Kamu, including their schemas and column descriptions, readme files, and popular queries.
Although Brian naturally prioritizes DeFi datasets, OAG in Kamu is domain agnostic. Any dataset added by our community becomes automatically available for querying.
Query generation: Brian passes the above context to its underlying language model, prompting it to generate a Postgres-compatible SQL query that answers the user’s prompt.
The model returns:
|
|
Query execution: This SQL is sent to Kamu’s query endpoint and returns a response in JSON:
|
|
The "output" part of the response is the actual result of the query, while the rest of the fields form a cryptographic proof of this request.
In this example we have a proof via reproducibility, where a specific Kamu node (identified by did:key:z6..fwZp W3C DID) commits to having correctly executed the query on the dataset did:odf:fe..4938 at a specific state snapshot (block) f1..3722.
Other types of proofs, including zero-knowledge can similarly be used in OAG to achieve desired effects.
For a detailed overview of the query proofs mechanism and its properties see our documentation.
Answer generation: LLM is asked to interpret the result for the user given the:
- Original user prompt
- Context with metadata about the datasets
- Generated SQL query
- Response data (in our case just
[{ "total_volume": 4039963082.961011 }])
LLM returns the final answer: The total trading volume of USDC between October 10th and October 20th, 2024, was approximately $4,039,963,083.
Both the final answer and the cryptographic commitment are saved in the chat history.
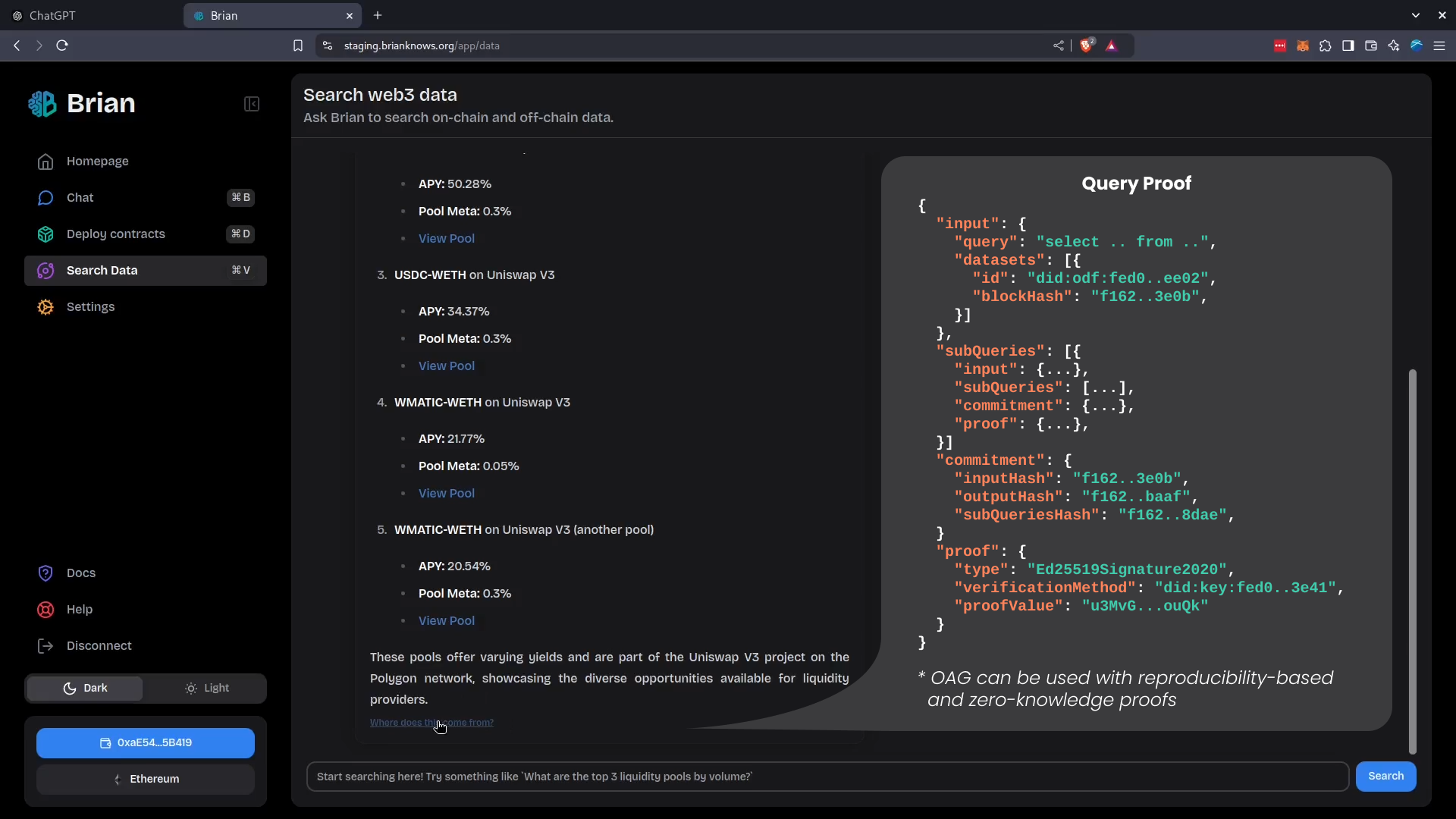
Proof saved alongside the agent's chat history
A hyperlink that Brian includes into the response allows users to quickly decode the proof and audit the query in Kamu’s Web UI.
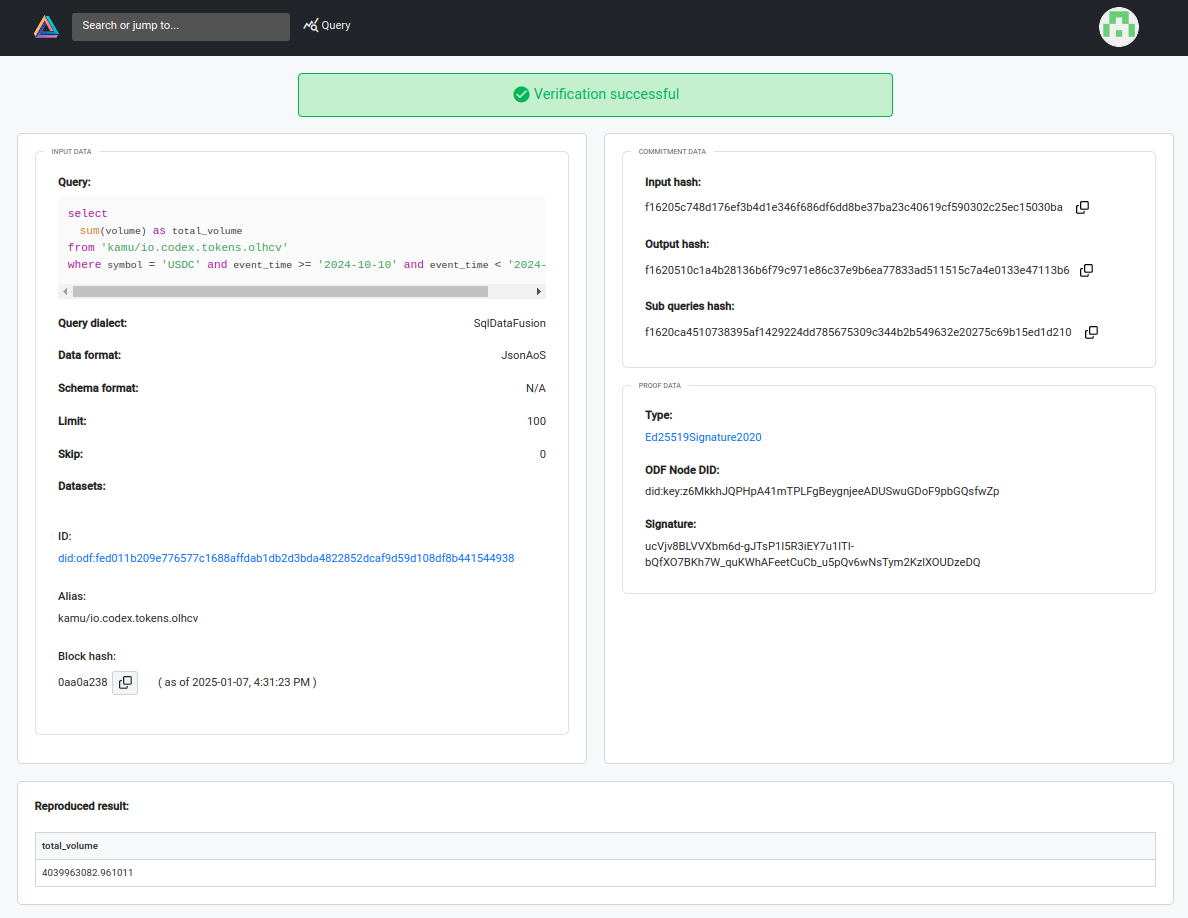
Auditing proof in Kamu Web UI
User can see:
- Which SQL query was executed
- What datasets and what snapshots of their state were used in the computation
- The result data that was reproduced identically to the past query
- The validation status of the proof, that ties the response to one or more nodes that executed the query
The ability of Kamu to provide indefinite reproducibility of queries even for fast-moving datasets relies on ledgerized data structure of the Open Data Fabric protocol. You can find more details in the ODF specification.
Current Limitations #︎
Kamu node does not yet provide the Proof<S> - a proof of executing context gathering phase and returning the most relevant datasets without any additions and omissions correctly. A reproducibility-based proof similar to the query proof Proof<Q> will be soon provided by anchoring the state of all “known datasets” of a node in an ODF dataset and using deterministic embeddings generation and vectorized search algorithms.
OAG vs. RAG #︎
While in RAG the model has to infer the answer directly from unstructured context data, in OAG the model generates query code and delegates the execution to an analytical system. OAG thus can work with much larger volumes of data that would otherwise never fit into the RAG context. This also significantly decreases the likelihood of hallucinating because most computations are performed by a deterministic system.
When it comes to structured data, OAG can work with significantly wider range of questions, including:
- Point-in-time and time-range questions
- Complex filters
- Statistical aggregations (medians, quantiles, OLAP cubes etc.)
In RAG it’s often hard to understand if LLM have made a correct conclusion based on the context data. Verifying this would require a human to analyze the entire context themselves, defeating the purpose. OAG offers superior auditability and provenance. Even if the answer requires processing terabytes of data - the generated query can be easily inspected and understood. The oracle system can also provide ways to also check if the query is using reliable data sources. As the query usually would aggregate many data points into an easily digestible statistical summary or a chart - it’s a lot easier for humans to check if the LLM’s interpretation of a result is correct.
In OAG, proofs introduce accountability. A query proof described above allows users to hold data providers and the parties that executed the query forever accountable for validity of the results. They can expose any attempts to alter or withhold data and thus become building blocks for penalizing malicious actors. Succinct cryptographic proofs provided by Kamu remain small even when result includes millions of data points, and thus can be cheaply stored alongside the chat history of agent responses.
OAG and Kamu for Data Supply Chain Verifiability #︎
The verifiability aspect of OAG is subtle yet transformative. Today companies pay huge sums for data APIs that don’t offer a single mechanism to hold the API provider accountable for correctness of their data. But as the world increases its reliance on real-time data and taps into more independent data sources - we will inevitably need to consider the consequences a presence of a few malicious actors may lead to in such a system.
While OAG can work with any verifiable database, we are especially excited about the properties it unlocks in combination with a decentralized data processing network like Kamu. Through its use of verifiable stream processing, Kamu extends OAG’s verifiability from a single query to cover an entire data supply chain.
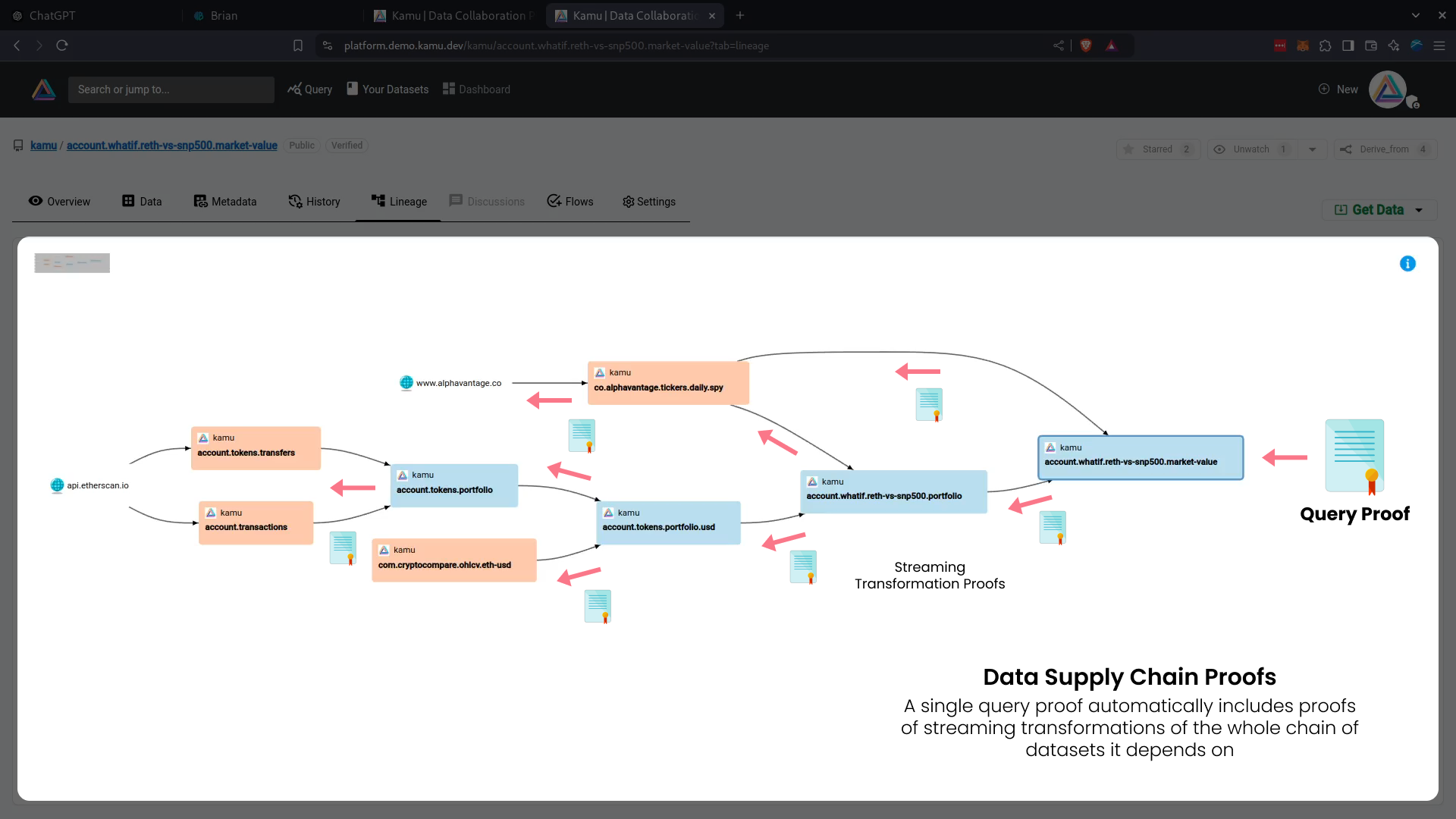
Data supply chain verifiability
Data from a reputable publisher or a blockchain can be processed by multiple third parties, cleaned and combined into higher-order more useful datasets that AI agents will naturally prefer to work with when mining for answers. But thanks to Kamu, the proof of a single query will automatically include provenance proofs of the entire supply chain, no matter how many hands the data went through!
We believe that Kamu and OAG can help elevate the state of data exchange from all of us just scrambling to get any satisfactory data to get by, to us collectively caring about the quality of data and where it comes from, and inventing new ways to organize efficient and trustworthy data supply chains on a global scale.
Role of OAG in AI and Data Economy #︎
We believe that conversational AI agents will soon become the primary way of how humans interact with data. We will increasingly rely on AI to source and distill important information for us. It is therefore important to make sure AI agents play nicely with the global data economy and that all incentives are aligned.
We unfortunately see a big problem in how big AI companies apply RAG today. With LLMs providing us the results we need, many users might no longer feel the need to open the web pages where RAG sourced the information from. This means that the websites RAG sourced data from start losing their traffic and ad revenue. We may soon see data brokers banning AI agents on their websites. This may in turn make major LLM companies use their virtually bottomless pockets to invest into their own proprietary data pipelines. With legislation around AI and IP rights still stuck in limbo, such a degree of centralization would be catastrophic.
We have previously shown [1][2] how a decentralized system like Kamu offers a better foundation for data economy:
- Through federated querying it allows us to efficiently combine data from multiple independent sources without the need to move data into one place
- Integrated provenance makes answers based on official reputable sources more valuable than unverifiable data from proprietary sources
- Verifiable pipelines allow data sourcing, cleaning, and composition to be crowd-sourced to a global community that can self-organize into a new generation of more transparent data brokers and aggregators.
Now with OAG we extend these properties to the AI economy.
Once again, verifiable provenance is playing the key role. After all, a query proof that tells us where every bit of data came from and who participated in computations is the exact information we need to fairly compensate everyone involved.
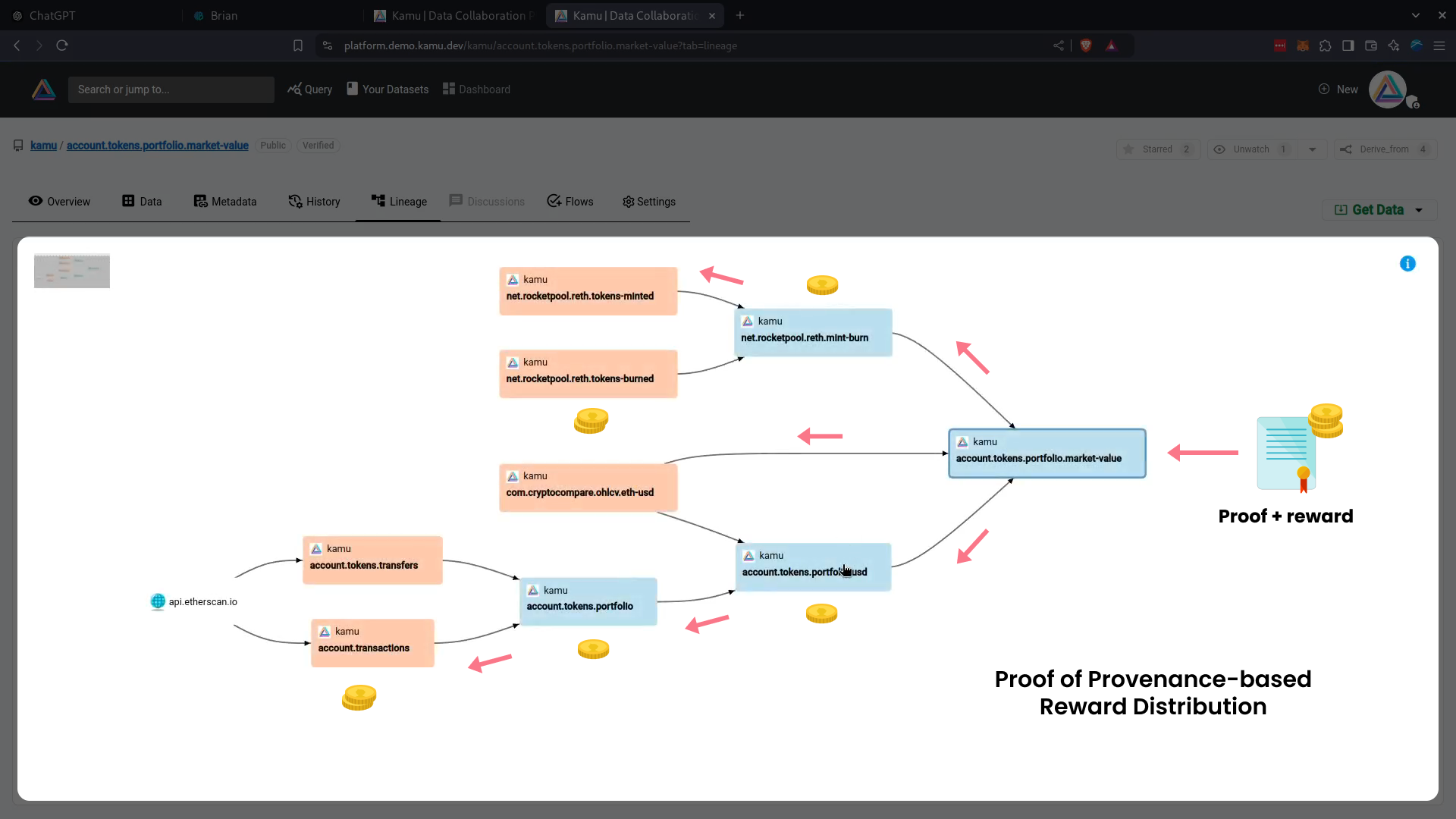
Provenance-based reward distribution
Provenance provides us a quantifiable way to distribute the revenue upstream to every participant of a data supply chain:
- Data publishers
- Storage and compute providers
- And the global community that builds and maintains the processing pipelines.
Future work #︎
The first OAG prototype has exceeded our expectations, but we have many more ideas to try:
- Agentic exploratory data analysis - to help with one of the biggest problems today where LLM sometimes struggle to filter data correctly without engough hints about the specific values present in data, we want the agent to be able to decide when it doesn’t have sufficient information to form a query and needs to perform intermediate steps to explore the content of candidate datasets.
- Progressive context expansion via knowledge/semantic graph - to help LLM generate correct
JOINs between datasets in separate domains we want to extend the metadata with semantic annotations (e.g. RDF). - Fuzzy querying - where SQL layer on Kamu’s side could notice and auto-correct typical mistakes in queries
- Fine-tuning with OAG-in-the-loop - as we believe best results can be achieved when LLM is trained in conjunction with an oracle and learns how to use it for best advantage.
Thanks for reading! Please give Brian AI agent a try and let us know what you think on Discord!

